Enterprise AI Data Infrastructure: How Organizations Build Trusted Data Foundations for Production AI
Enterprise AI data infrastructure is the foundation that determines whether production AI systems can retrieve trusted context, respect access controls, scale across business units, and operate reliably. As organizations deploy LLM applications, RAG systems, AI agents, and AI-enabled workflows, the data layer becomes the control plane between enterprise knowledge and operational intelligence.
Why Enterprise AI Data Infrastructure Matters
Most production AI failures are not caused by the model alone. They are caused by weak data foundations: stale documents, fragmented knowledge, inconsistent permissions, poor metadata, disconnected systems, unreliable ingestion pipelines, missing lineage, weak retrieval quality, and no operational visibility into how enterprise context is being used. A capable model cannot compensate for untrusted, incomplete, or poorly governed data infrastructure.
Enterprise AI data infrastructure solves this problem by creating a trusted foundation for AI systems to access, retrieve, interpret, and act on enterprise knowledge. It connects data platforms, documents, APIs, business systems, vector databases, metadata layers, identity controls, governance policies, and observability pipelines into a production-ready architecture. For enterprises scaling AI across functions, this layer is not optional. It is what turns isolated AI prototypes into reliable, secure, and reusable AI capabilities.
Key Insight
Enterprise AI becomes trustworthy when the data layer is not treated as a collection of sources, but as a governed, permission-aware, observable infrastructure system designed for production AI.
What Enterprise AI Data Infrastructure Actually Is
Enterprise AI data infrastructure is the set of systems, pipelines, governance controls, metadata models, retrieval layers, and operational processes that allow AI systems to use enterprise data safely and effectively. It includes source system integration, document ingestion, data normalization, metadata enrichment, permission mapping, vector indexing, semantic retrieval, hybrid search, data lineage, knowledge freshness, data quality checks, observability, and access control enforcement.
Unlike traditional analytics infrastructure, AI data infrastructure must support dynamic context assembly. LLM applications and AI agents do not simply query a report. They retrieve context, reason over sources, summarize information, call tools, personalize responses, and sometimes take action. That means the data infrastructure must be accurate, secure, explainable, and responsive enough to support real-time or workflow-critical AI behavior.
Data Connectivity
Connects enterprise systems, data warehouses, document stores, knowledge bases, APIs, product databases, and operational tools.
Knowledge Processing
Transforms raw content into AI-ready context through cleaning, chunking, metadata enrichment, embedding, indexing, and validation.
Governed Retrieval
Ensures AI systems retrieve only relevant, current, permission-safe, and policy-compliant context for each user or workflow.
Operational Visibility
Tracks retrieval quality, source freshness, access decisions, index health, data lineage, query patterns, and production AI usage.
Why Traditional Data Platforms Are Not Enough for Production AI
Traditional data platforms were designed primarily for analytics, reporting, operational applications, and human decision support. They organize data for dashboards, queries, pipelines, and business intelligence. Production AI systems introduce different requirements. They need to retrieve semantically relevant context, assemble evidence from multiple sources, respect user-level permissions, evaluate content quality, maintain freshness, and expose traceability for generated outputs.
A data warehouse may contain clean structured data, but an AI assistant may also need policy documents, support tickets, product manuals, customer records, logs, code repositories, knowledge base articles, meeting notes, and workflow history. These assets often live in different systems with different permission models and quality standards. Enterprise AI data infrastructure creates a unified architecture for making that knowledge usable without weakening governance.
Enterprise Signal
If an AI system cannot prove where its context came from, when it was updated, who was allowed to access it, and why it was retrieved, the data infrastructure is not production mature.
From Data Storage to Context Delivery
AI systems do not need data storage alone. They need context delivery: the ability to retrieve the right information, at the right time, for the right user, with the right permissions, and with evidence that the response can be trusted.
From Centralized Data to Federated Knowledge
Enterprise knowledge is rarely stored in one place. AI data infrastructure must support federated retrieval across cloud platforms, SaaS systems, internal databases, document repositories, and operational tools while preserving source-level governance.
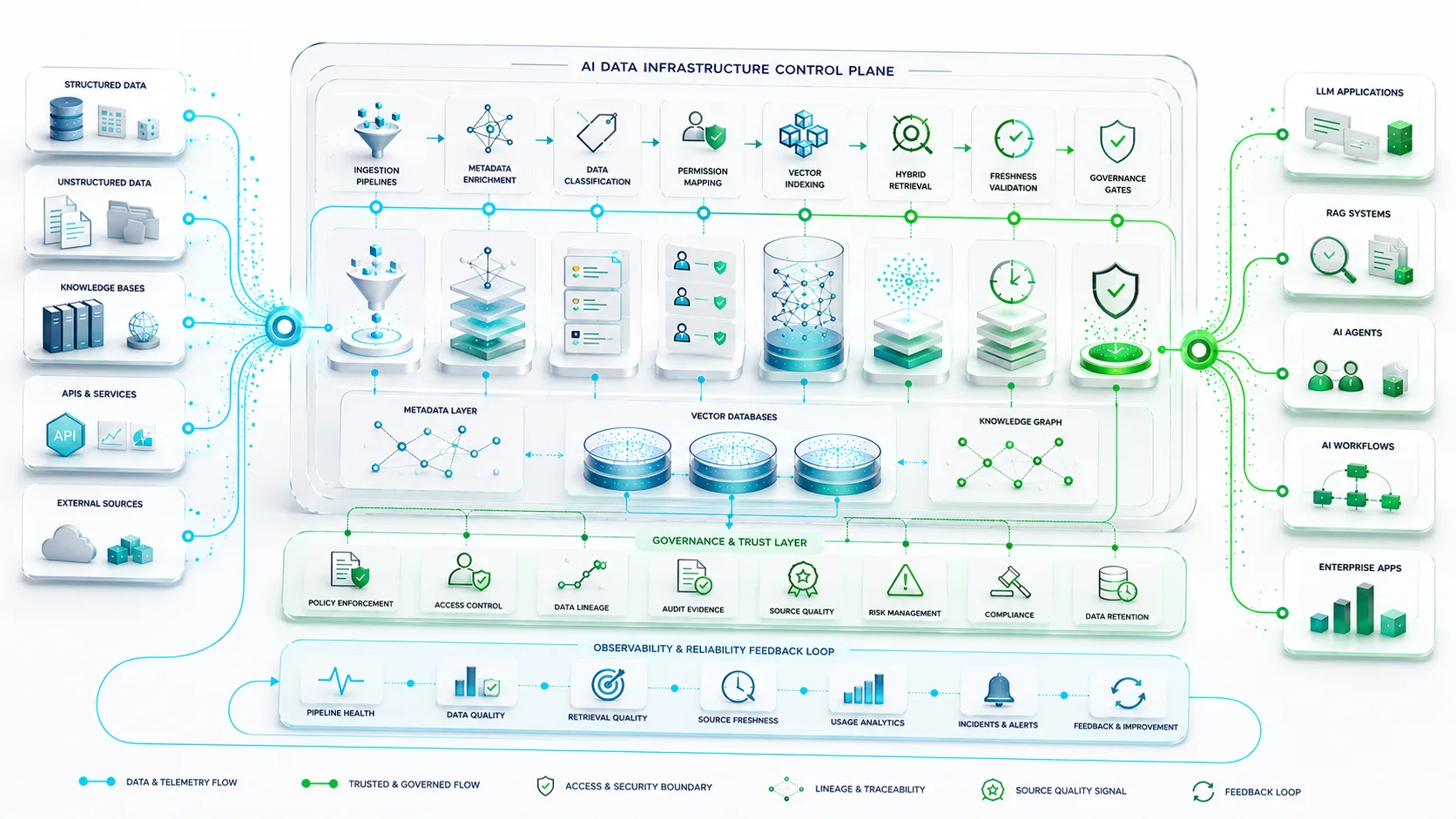
Core Layers of Enterprise AI Data Infrastructure
A mature enterprise AI data infrastructure should be layered. Each layer handles a distinct responsibility, but all layers must operate together. The architecture should support RAG systems, AI agents, LLM applications, AI search, workflow automation, and production AI operations without requiring every team to rebuild the same foundations.
Reference AI Data Infrastructure Layers
The Retrieval Layer Is a Production Control Point
The retrieval layer should not be treated as a simple search utility. It is a control point where relevance, permissions, freshness, source ranking, data policy, and evidence quality are enforced before information enters the AI context window.
The Metadata Layer Determines AI Quality
Metadata helps AI systems understand source type, authoritativeness, ownership, sensitivity, department, date, version, customer segment, product area, and access boundaries. Without strong metadata, retrieval becomes less precise and governance becomes harder to enforce.
RAG Data Infrastructure for Enterprise Knowledge
Retrieval-augmented generation is one of the most common enterprise AI patterns, but production RAG requires more than a vector database. Enterprises need ingestion workflows, chunking strategy, embedding pipelines, hybrid retrieval, permission filters, source ranking, context evaluation, freshness checks, and observability. RAG becomes reliable when it is designed as knowledge infrastructure.
Ingestion Pipelines
Move documents and records into AI-ready formats while preserving source metadata, permissions, ownership, version, and lifecycle state.
Vector and Hybrid Search
Combine semantic retrieval with keyword, metadata, graph, and structured filters to improve precision and explainability.
Retrieval Evaluation
Measure whether retrieved sources are relevant, current, authorized, complete, and sufficient for the AI system’s task.
RAG Infrastructure Principle
RAG quality depends less on storing embeddings and more on the full retrieval lifecycle: source quality, metadata, permissions, ranking, freshness, evaluation, and observability.
Permission-Aware Data Access for AI Systems
AI data infrastructure must respect enterprise access controls. If a user cannot access a document, record, customer account, code repository, or internal policy in the source system, the AI system should not expose that information through retrieval or summarization. Permission-aware retrieval is one of the most important security requirements for production AI.
Identity Mapping
The AI data layer should map users, groups, roles, service accounts, agents, and workflows to source-system permissions. This allows AI systems to retrieve context based on the requester’s authority rather than relying on broad system-level access.
Policy Enforcement at Retrieval Time
Permissions should be enforced when context is retrieved, not only when data is ingested. This matters because user access can change, documents can become restricted, workflows can move into higher risk tiers, and AI agents may operate under delegated permissions.
Access Control Guardrail
Enterprise AI data infrastructure should never use a single broad-access retrieval account as a shortcut around source-system permissions.
Key Takeaways
- ✓ Enterprise AI data infrastructure is the trusted foundation for LLM applications, RAG systems, AI agents, and production AI workflows.
- ✓ Production AI requires more than data storage. It requires governed context delivery, metadata, retrieval quality, access control, freshness, and observability.
- ✓ RAG infrastructure should be designed as enterprise knowledge infrastructure, not as a standalone vector database deployment.
- ✓ Permission-aware retrieval is critical because AI systems must respect source-system access boundaries for users, agents, and workflows.
- ✓ Mature AI data infrastructure connects data engineering, security, governance, LLMOps, AI observability, and enterprise architecture into one operating model.
Metadata, Lineage, and Source Trust
AI systems need to understand more than the content of a document or record. They need to understand where it came from, who owns it, when it was updated, whether it is authoritative, who can access it, and whether it is appropriate for a specific workflow. Metadata and lineage make AI outputs easier to trust, evaluate, and govern.
Source Authority
Not every source should have equal weight. A final approved policy, a customer contract, an internal draft, a support forum, and a historical ticket may all contain relevant text, but they carry different authority levels. AI data infrastructure should rank and filter sources based on authority and context.
Data Lineage for AI Responses
Lineage helps teams trace AI outputs back to the underlying sources, retrieval query, embedding version, index state, prompt, model, and policy decisions. This evidence is essential for debugging, quality assurance, compliance, and incident response.
Trust Principle
A production AI system should not only answer. It should be able to show which enterprise knowledge supported the answer and why that knowledge was allowed into context.
Data Freshness and Lifecycle Management
AI systems can quickly become unreliable when they rely on stale data. Enterprise policies change, product documentation evolves, customer records update, pricing shifts, security guidance changes, and operational procedures mature. AI data infrastructure must manage freshness, expiration, re-indexing, versioning, and content lifecycle with production discipline.
Freshness Policies
Define how often sources are refreshed, which sources require real-time access, and when stale content should be excluded.
Index Lifecycle
Manage embedding versions, vector indexes, re-indexing jobs, deleted content, metadata changes, and access-control updates.
Source Deprecation
Retire outdated documents, superseded policies, inactive knowledge bases, duplicate records, and unsupported internal guidance.
Change Monitoring
Track content changes that may affect AI behavior, retrieval relevance, policy enforcement, or answer quality.
AI Data Observability and Retrieval Monitoring
AI observability must include the data and retrieval layer. Teams need to know which sources were retrieved, how often they were used, whether retrieval quality is declining, whether stale content entered context, whether permission filters worked, and whether AI outputs were grounded in valid evidence. Without retrieval observability, teams cannot diagnose many production AI failures.
Retrieval Metrics
Track query patterns, source usage, retrieval relevance, top-k quality, empty results, stale-source rate, permission-denied events, fallback retrieval, and user feedback on answer usefulness.
Data Pipeline Metrics
Monitor ingestion success, indexing latency, embedding failures, metadata completeness, duplicate content, source freshness, document deletion propagation, and access-control synchronization.
Observability Guardrail
If teams cannot observe the sources and retrieval decisions behind AI outputs, they cannot reliably improve quality, govern risk, or investigate incidents.
Security and Governance for AI-Ready Data
Enterprise AI data infrastructure is a security boundary. It handles sensitive documents, customer data, operational records, employee information, proprietary knowledge, source code, compliance policies, and business workflows. Security and governance must be built into ingestion, indexing, retrieval, logging, caching, and model context assembly.
Data Classification
Classify sources by sensitivity, business criticality, compliance exposure, customer impact, and allowed AI usage.
Policy-Aware Retrieval
Apply policy rules before context reaches the model, especially for regulated, confidential, or high-impact workflows.
Audit Evidence
Capture source usage, permission checks, retrieval decisions, policy outcomes, and data access trails for accountability.
Common Mistakes
Many enterprises underestimate the data infrastructure required for production AI. They build an impressive prototype with a small document set, then struggle when the system needs to scale across departments, permissions, source systems, data quality issues, and production reliability requirements.
- Treating the vector database as the whole architecture. Vector storage is only one part of AI data infrastructure. Enterprises also need ingestion, metadata, governance, evaluation, and observability.
- Ignoring source permissions. AI systems must respect user and workflow access boundaries at retrieval time.
- Using stale or unverified knowledge. Outdated content can cause inaccurate responses, poor workflow decisions, and governance risk.
- Skipping metadata strategy. Poor metadata weakens retrieval quality, source trust, ranking, filtering, and compliance evidence.
- Failing to monitor retrieval quality. Teams cannot improve RAG systems if they do not track what was retrieved and whether it helped.
- Creating one-off knowledge pipelines. Enterprises need reusable AI data infrastructure patterns, not isolated pipelines for every use case.
Enterprise Architecture Perspective
From an enterprise architecture perspective, AI data infrastructure is the bridge between enterprise knowledge and AI execution. It connects data platforms, identity systems, knowledge repositories, model orchestration, RAG pipelines, AI agents, governance controls, observability, and production operations. Without this bridge, AI systems operate on fragmented context and create unmanaged risk.
The strongest architecture treats AI data infrastructure as a reusable platform layer. Business teams should not have to rebuild ingestion, metadata, retrieval, permission filtering, evaluation, and audit trails for every AI use case. Instead, enterprises should create shared capabilities that allow AI systems to access trusted knowledge consistently and safely.
Architecture Principle
Enterprise AI data infrastructure should make trusted knowledge reusable, permission-aware, observable, governed, and production-ready across AI systems.
Implementation Strategy for Enterprise AI Data Infrastructure
Enterprises should implement AI data infrastructure in phases. The goal is not to centralize every knowledge asset immediately. The goal is to create reusable foundations for trusted context delivery, then expand coverage based on priority use cases, risk level, and production demand.
Phase 1: Map AI Use Cases to Data Needs
Identify which AI systems need which data sources, documents, records, APIs, and knowledge repositories. Classify sources by sensitivity, owner, freshness requirement, permission model, and business criticality.
Phase 2: Build AI-Ready Knowledge Pipelines
Create ingestion, cleaning, chunking, metadata enrichment, embedding, indexing, and validation pipelines. Preserve source permissions, lineage, version, and ownership during processing.
Phase 3: Implement Governed Retrieval
Add permission-aware retrieval, hybrid search, source ranking, freshness filters, policy controls, context validation, and retrieval evaluation. Ensure AI systems retrieve the right evidence for the right workflow.
Phase 4: Operationalize Monitoring and Improvement
Monitor retrieval quality, source freshness, index health, metadata completeness, permission checks, and user feedback. Use production signals to improve data quality, retrieval patterns, and governance policies over time.
Implementation Checklist
Foundation
- Inventory AI data sources and owners
- Classify sensitivity and freshness needs
- Map source-system permissions
- Define metadata and lineage requirements
Retrieval Architecture
- Create ingestion and indexing pipelines
- Implement hybrid and semantic retrieval
- Apply permission-aware filtering
- Evaluate retrieval quality continuously
Operations
- Monitor source freshness and index health
- Track retrieval relevance and source usage
- Capture audit evidence for AI context
- Improve data pipelines from production signals
Measuring AI Data Infrastructure Maturity
AI data infrastructure maturity should be measured by how reliably the enterprise can deliver trusted, permission-safe, and relevant context to production AI systems. The strongest organizations do not only know which sources are connected. They know whether those sources are current, authorized, useful, observable, and governed.
Metrics to Track
How YggyTech Helps
YggyTech helps enterprises design and implement AI data infrastructure for production AI systems. We help organizations move from fragmented data sources and experimental RAG pipelines to trusted, governed, observable, and scalable AI knowledge foundations.
AI Data Architecture Strategy
We define AI data blueprints, source prioritization, metadata models, permission strategies, RAG infrastructure patterns, and production readiness roadmaps.
RAG and Knowledge Infrastructure
We design ingestion pipelines, vector and hybrid retrieval, metadata enrichment, source ranking, evaluation workflows, and retrieval observability.
Governance and Operations Integration
We connect AI data infrastructure with identity, governance, security, observability, LLMOps, AI assurance, and production operations.
Our expertise spans enterprise AI, AI infrastructure, cloud architecture, data systems, LLMOps, cybersecurity, DevOps, software architecture, AI governance, and scalable systems. That systems-level perspective matters because AI data infrastructure is not only a pipeline problem. It is the trust foundation for production AI.
Build the Data Foundation Production AI Can Trust
YggyTech helps technology leaders build enterprise AI data infrastructure that delivers trusted context, governed retrieval, permission-aware access, source observability, and scalable knowledge foundations for production AI systems.
Talk to YggyTechFAQs About Enterprise AI Data Infrastructure
What is enterprise AI data infrastructure?
Enterprise AI data infrastructure is the architecture that enables AI systems to access trusted, governed, permission-aware, and production-ready enterprise data. It includes ingestion, metadata, vector indexing, retrieval, access control, lineage, observability, and governance.
Why is enterprise AI data infrastructure important?
Enterprise AI data infrastructure is important because production AI systems depend on accurate context, secure retrieval, source freshness, data quality, metadata, permissions, and auditability. Without this foundation, AI systems become unreliable and difficult to govern.
How does AI data infrastructure support RAG systems?
AI data infrastructure supports RAG systems through ingestion pipelines, chunking, embedding generation, vector and hybrid search, metadata filtering, permission-aware retrieval, source ranking, freshness checks, and retrieval quality monitoring.
What is permission-aware retrieval?
Permission-aware retrieval ensures that AI systems only retrieve and use information the requesting user, agent, or workflow is authorized to access. It prevents AI systems from bypassing source-system access controls.
How can enterprises start building AI-ready data infrastructure?
Enterprises should start by mapping AI use cases to data sources, assigning data owners, classifying sensitivity, defining metadata standards, preserving permissions, building ingestion and retrieval pipelines, and monitoring retrieval quality in production.

Sarah Anderson
Head of Content
Sarah leads the content strategy at Yggy Tech, bringing 10+ years of experience in technology writing and editorial direction.