Inference Mesh Architecture: Scaling Enterprise AI Across Hybrid Cloud Environments
Enterprise AI is entering a new operational era.
Organizations are no longer deploying a single model within a single cloud environment. Instead, modern enterprises are operating AI ecosystems that span multiple cloud providers, on-premises infrastructure, edge environments, sovereign cloud regions, and specialized GPU clusters.
This expansion is creating an entirely new infrastructure challenge.
How do organizations reliably deliver AI inference across increasingly distributed enterprise environments?
Traditional model-serving architectures were not designed for the scale, complexity, and operational demands of modern enterprise AI.
As inference becomes the dominant cost center and operational workload within AI systems, enterprises are adopting a new architectural pattern known as the Inference Mesh.
Inference Mesh Architecture provides a distributed operational layer that intelligently routes, governs, observes, and optimizes AI inference workloads across hybrid cloud environments.
Much like service meshes transformed cloud-native applications, inference meshes are becoming a foundational infrastructure layer for enterprise AI operations.
What Is an Inference Mesh Architecture?
An Inference Mesh is a distributed infrastructure architecture that manages how AI inference requests are routed, executed, monitored, secured, and optimized across multiple AI serving environments.
Rather than binding applications to specific models or endpoints, the mesh introduces an intelligent routing layer between AI consumers and AI services.
This layer dynamically determines:
- Which model should handle a request
- Where inference should execute
- How workloads should be distributed
- Which governance policies apply
- How costs should be optimized
- How reliability should be maintained
The result is a flexible and scalable AI operating environment.
Why Traditional Inference Architectures Are Failing
Early enterprise AI deployments typically relied on direct integrations with individual models.
Applications connected directly to:
- Foundation model APIs
- Private inference endpoints
- On-premises model servers
- Cloud-hosted AI platforms
As AI adoption grows, this approach becomes increasingly difficult to manage.
Organizations encounter challenges such as:
- Model sprawl
- Vendor fragmentation
- Latency variability
- GPU resource constraints
- Governance inconsistencies
- Cost inefficiencies
- Operational complexity
Inference Mesh Architecture addresses these issues through centralized orchestration and distributed execution.
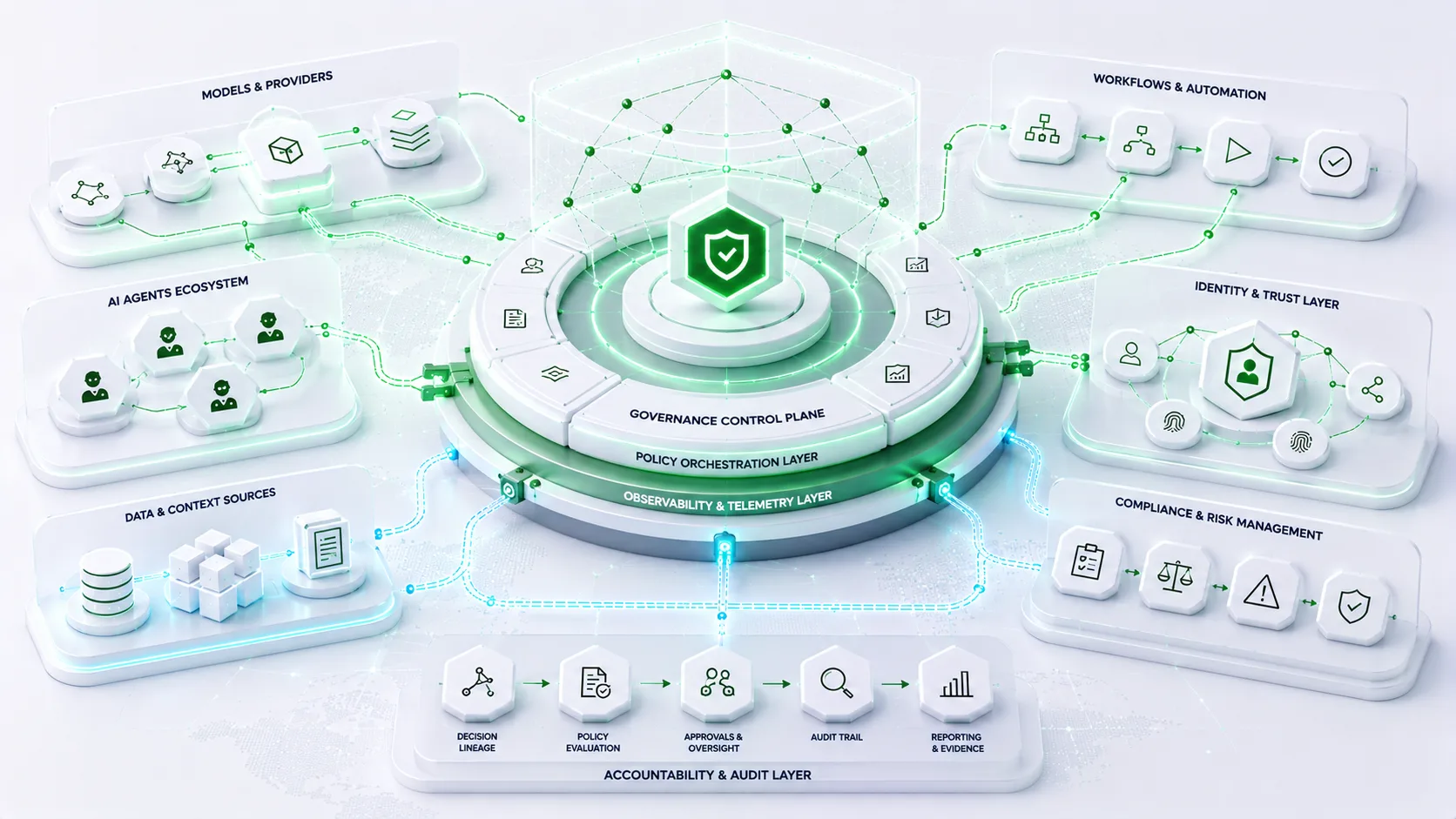
The Core Components of an Inference Mesh
1. Inference Control Plane
The control plane serves as the centralized intelligence layer.
It manages:
- Routing policies
- Model registries
- Governance controls
- Observability systems
- Identity frameworks
- Operational policies
The control plane acts as the operational brain of the inference mesh.
2. Routing Layer
The routing layer determines where requests should execute.
Routing decisions may consider:
- Latency requirements
- Model capabilities
- Regional availability
- GPU utilization
- Operational costs
- Compliance requirements
This enables intelligent workload placement across the enterprise.
3. Distributed Model Serving Layer
The serving layer contains the actual inference endpoints.
These may include:
- Public cloud models
- Private foundation models
- Fine-tuned enterprise models
- Edge inference services
- Specialized AI accelerators
The mesh abstracts these environments into a unified operational platform.
4. Observability Layer
Observability provides visibility into inference operations.
Organizations monitor:
- Latency
- Throughput
- GPU utilization
- Request volumes
- Error rates
- Model performance
- Cost metrics
This visibility is essential for enterprise-scale operations.
5. Governance Layer
Inference traffic increasingly requires governance oversight.
Governance services enforce:
- Data policies
- Security controls
- Compliance requirements
- Access permissions
- Operational guardrails
Governance becomes embedded directly into inference workflows.
Hybrid Cloud as the New AI Reality
Few enterprises operate exclusively within a single cloud environment.
Modern AI deployments often span:
- AWS
- Microsoft Azure
- Google Cloud
- Private clouds
- Edge environments
- Regional sovereign clouds
Different workloads have different requirements.
For example:
- Customer-facing applications may prioritize latency.
- Regulated workloads may require regional execution.
- Large-scale training environments may prioritize GPU availability.
An inference mesh enables these environments to operate as a single logical platform.
Intelligent Model Routing
One of the most valuable capabilities of an inference mesh is dynamic model routing.
Instead of statically assigning requests to models, the mesh can evaluate:
- Task complexity
- Cost considerations
- Latency targets
- Policy requirements
- Model performance
This enables organizations to optimize inference outcomes automatically.
A simple request might route to a lightweight model, while a complex reasoning task could be directed to a larger foundation model.
Cost Optimization Through Inference Orchestration
Inference costs are becoming one of the largest expenses in enterprise AI programs.
Inference meshes provide cost-management capabilities through:
- Model selection optimization
- Load balancing
- GPU utilization management
- Traffic shaping
- Resource allocation policies
This allows enterprises to balance performance and economics.
Inference Mesh and AI Reliability
Reliability is increasingly critical for AI-powered business services.
Inference meshes support resilience through:
- Failover routing
- Multi-region execution
- Redundant inference pathways
- Traffic rerouting
- Operational observability
These capabilities help ensure continuous service availability.
Supporting Multi-Agent Systems
Enterprise AI is moving toward multi-agent architectures.
These environments generate significantly more inference traffic than traditional AI systems.
Agents may continuously:
- Reason
- Plan
- Retrieve information
- Validate decisions
- Coordinate actions
An inference mesh provides the scalable infrastructure necessary to support these workloads.
Inference Mesh and AI Control Planes
AI control planes and inference meshes are increasingly converging.
Control planes provide governance and orchestration.
Inference meshes provide execution intelligence.
Together, they create a complete enterprise AI operating model capable of managing both governance and infrastructure operations.
Enterprise Use Cases
Global Customer Platforms
Organizations route requests to the nearest inference location while maintaining governance requirements.
Financial Services
Regulated workloads can execute within approved jurisdictions while benefiting from centralized management.
Manufacturing Operations
Edge inference systems can coordinate with centralized AI services across distributed facilities.
Healthcare Systems
Inference meshes support secure and compliant AI deployment across complex operational environments.
Multi-Agent Enterprise Platforms
Agent ecosystems rely on distributed inference infrastructure to support autonomous operations.
Key Metrics for Inference Mesh Operations
- Inference latency
- Request success rates
- GPU utilization
- Traffic distribution efficiency
- Model routing effectiveness
- Cost per inference
- Operational availability
- Governance compliance rates
These metrics help organizations optimize both performance and operational efficiency.
Challenges Organizations Must Address
- Cross-cloud integration
- Vendor interoperability
- Observability complexity
- Governance consistency
- Latency management
- Infrastructure costs
- Operational scalability
Successfully implementing an inference mesh requires both architectural planning and operational maturity.
Building an Enterprise Inference Mesh Strategy
Leading organizations are investing in six foundational capabilities:
- Inference control planes
- Dynamic routing systems
- AI observability platforms
- Governance integration
- Hybrid cloud orchestration
- Reliability engineering practices
Together, these capabilities create a scalable AI infrastructure foundation.
The Future of Inference Mesh Architectures
As enterprise AI adoption accelerates, inference meshes will become a standard component of AI infrastructure stacks.
Future platforms will increasingly support:
- Autonomous inference optimization
- Predictive routing intelligence
- Cross-cloud workload orchestration
- AI-native infrastructure automation
- Real-time governance enforcement
- Self-optimizing inference networks
The organizations that establish inference mesh capabilities today will be better positioned to operate AI at enterprise scale tomorrow.
Key Takeaways
- Inference is becoming the operational core of enterprise AI.
- Traditional model-serving architectures struggle at enterprise scale.
- Inference meshes provide intelligent routing, governance, observability, and resilience.
- Hybrid cloud environments require distributed AI operating models.
- Inference meshes are emerging as foundational infrastructure for enterprise AI operations.
How YggyTech Helps
YggyTech helps organizations design and implement modern inference infrastructure through AI control planes, inference mesh architectures, observability platforms, governance frameworks, hybrid cloud orchestration systems, and enterprise AI operations strategies.
Our approach enables enterprises to scale AI reliably while maintaining governance, performance, and operational control across distributed environments.
Conclusion
The future of enterprise AI depends on infrastructure capable of operating across increasingly distributed environments.
Inference Mesh Architecture provides the operational foundation needed to route, govern, observe, secure, and optimize AI inference at scale.
As hybrid cloud environments become the norm, organizations that embrace inference mesh principles will gain the flexibility, resilience, and efficiency required to power the next generation of enterprise AI systems.
FAQs
What is an Inference Mesh Architecture?
An Inference Mesh is a distributed infrastructure layer that manages AI inference routing, governance, observability, and optimization across multiple execution environments.
Why do enterprises need inference meshes?
They help organizations scale AI inference across hybrid cloud environments while improving reliability, governance, performance, and cost efficiency.
How is an inference mesh different from a service mesh?
A service mesh manages application communication, while an inference mesh specifically manages AI inference traffic, model routing, and AI operational requirements.
What role does the control plane play?
The control plane manages routing policies, governance rules, observability systems, and operational intelligence across the inference environment.
How do inference meshes support multi-agent systems?
They provide scalable and intelligent inference infrastructure capable of handling the high-volume reasoning and coordination workloads generated by autonomous agents.

Mason Carter
Cloud & Infrastructure Engineer
Mason focuses on scalable cloud ecosystems, DevOps modernization, and secure distributed infrastructure. His insights at YGGY Tech explore resilient architecture design, Kubernetes operations, cybersecurity strategy, and enterprise scalability.