AI Inference Infrastructure: How Enterprises Scale Low-Latency, Cost-Efficient Production AI
AI inference infrastructure is the production architecture that allows enterprises to serve AI models with low latency, predictable cost, reliable throughput, and operational control. As AI moves from prototypes into customer-facing and workflow-critical systems, inference becomes one of the most important infrastructure layers in the enterprise AI stack.
Why AI Inference Infrastructure Matters
Most enterprise AI conversations begin with model capability, but production success depends on how efficiently those models are served. A model that performs well in a benchmark can still fail in production if inference latency is too high, GPU utilization is poor, cost per request is unpredictable, autoscaling is weak, or model endpoints cannot handle real workload patterns. AI inference infrastructure turns model capability into usable enterprise capacity.
Inference is where AI systems meet users, applications, workflows, APIs, and business expectations. Every request must be routed, authorized, processed, observed, optimized, and returned within acceptable performance boundaries. For customer support copilots, real-time search, fraud detection, internal knowledge systems, AI agents, and embedded product intelligence, inference architecture directly affects user experience and operating economics.
Key Insight
Enterprise AI does not scale only by choosing better models. It scales when the inference layer can deliver the right model response at the right latency, cost, reliability level, and governance boundary.
What AI Inference Infrastructure Actually Is
AI inference infrastructure is the set of systems, services, policies, and operational patterns used to serve AI models in production. It includes model serving endpoints, inference gateways, GPU and CPU resource pools, request routing, autoscaling, batching, caching, token management, model selection, observability, reliability controls, security policies, and cost governance.
For traditional software, infrastructure must host applications and manage traffic. For AI systems, infrastructure must also manage model behavior, variable response times, token usage, prompt size, retrieval context, model routing, accelerator capacity, cost per inference, and output quality. This makes inference infrastructure both a performance layer and an economic control layer.
Model Serving
Hosts AI models behind scalable endpoints with versioning, deployment controls, health checks, release gates, and rollback paths.
Request Routing
Routes requests across models, providers, regions, hardware tiers, and fallback paths based on workload requirements.
Performance Control
Optimizes latency, throughput, batching, concurrency, queue depth, caching, and accelerator utilization.
Cost Governance
Tracks token usage, compute consumption, model cost, provider spend, cache savings, and cost per business workflow.
Why Production AI Inference Is Harder Than Standard Application Scaling
Standard application scaling is usually based on predictable CPU, memory, request, and database patterns. AI inference introduces more variability. Request sizes can change dramatically based on prompt length, retrieved context, model type, output size, reasoning complexity, batch behavior, and concurrency spikes. Two requests to the same endpoint may have very different latency and cost profiles.
This variability creates infrastructure pressure. Enterprises need to decide when to use large models, smaller models, specialized models, local inference, managed APIs, GPU serving, CPU serving, caching, batching, streaming, async processing, or fallback routes. Without a clear inference architecture, teams either overpay for performance or underdeliver on user experience.
Enterprise Signal
Inference architecture becomes business-critical when AI response time, cost per request, model reliability, or endpoint availability affects customer experience, operational workflows, or revenue-generating systems.
From Traffic Scaling to Workload-Aware Scaling
AI infrastructure should scale based on workload characteristics, not only request volume. The system must understand prompt size, token budget, model latency, GPU availability, request priority, and expected output length.
From One Model Endpoint to Intelligent Model Routing
Many enterprise use cases do not need the largest model for every request. Intelligent routing can send simple requests to efficient models, complex reasoning to stronger models, sensitive workloads to private endpoints, and low-priority jobs to asynchronous queues.
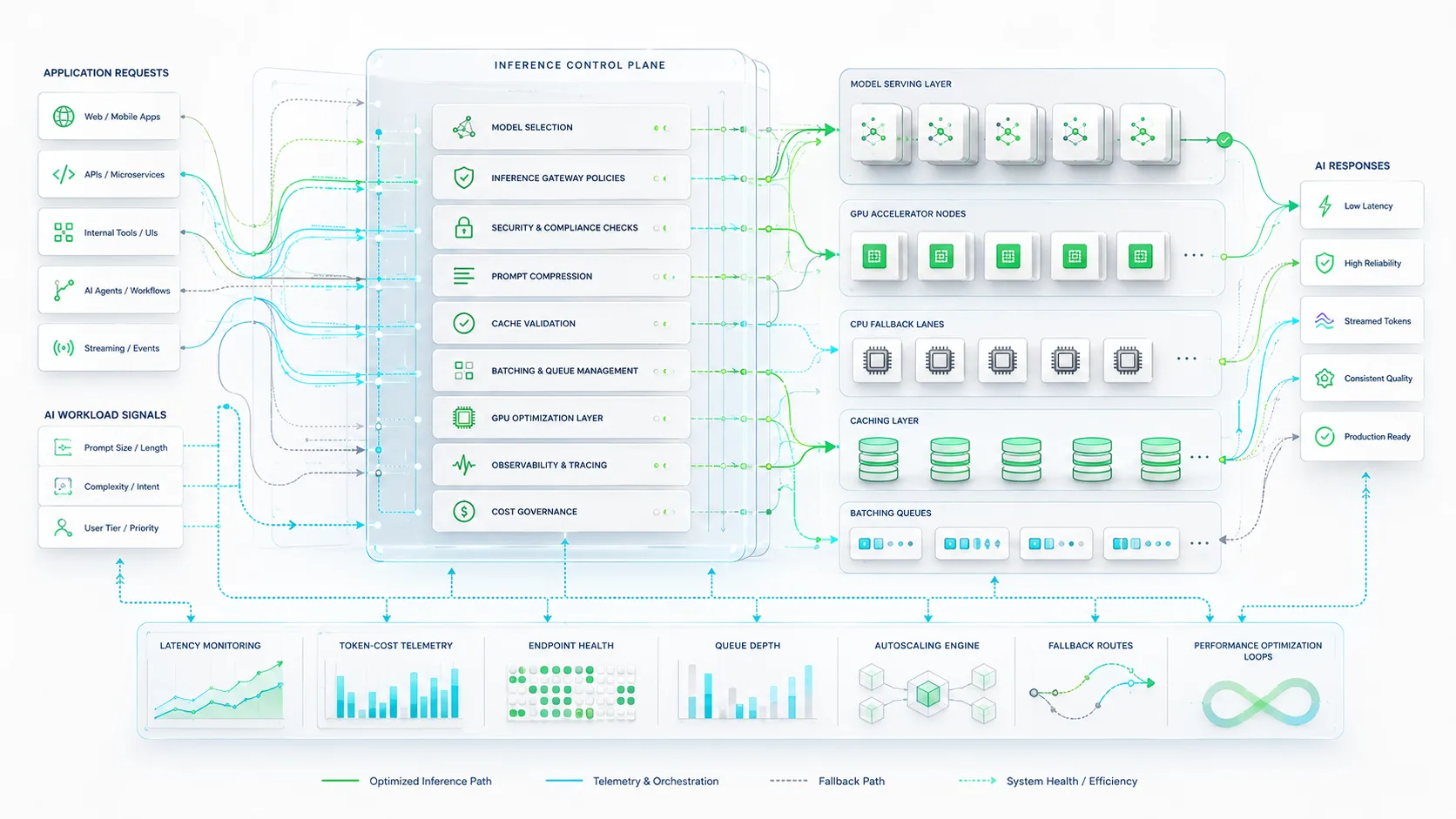
Core Layers of AI Inference Infrastructure
A mature AI inference infrastructure should be designed as a layered architecture. Each layer handles a different production concern: traffic entry, model routing, serving, resource orchestration, optimization, observability, security, and governance. The architecture should support both managed model APIs and self-hosted model serving where business, privacy, cost, or latency requirements demand it.
Reference Inference Architecture Layers
The Inference Gateway Is the Control Point
An inference gateway gives enterprises a centralized control point for routing, policy, rate limits, security, observability, cost tracking, and provider abstraction. Without a gateway, every application integrates with models differently, creating inconsistent controls and fragmented cost visibility.
Model Serving Must Be Observable by Design
Serving infrastructure should expose latency, queue time, token usage, GPU utilization, model version, cache hit rate, failure rate, fallback usage, and cost per request. These signals are essential for production reliability and economic governance.
Low-Latency AI: Designing for Real-Time User Experience
Low-latency AI is not achieved by hardware alone. It requires architecture decisions across model selection, context size, network placement, caching, batching, streaming, prompt design, retrieval performance, queue management, and endpoint capacity. Enterprises should define latency targets by use case instead of forcing one standard across all AI workloads.
Interactive Workloads
Customer copilots, search experiences, chat systems, and product UI features require fast initial response and predictable completion time.
Workflow Automation
Agent workflows and back-office tasks may tolerate higher latency if reliability, auditability, and cost efficiency are stronger.
Batch Processing
Document analysis, enrichment, classification, and offline evaluation can be optimized for throughput and cost over immediate response.
Latency Principle
Enterprises should optimize for the latency users actually experience: time to first token, time to useful answer, workflow completion time, and recovery time after failure.
GPU Optimization and AI Workload Orchestration
GPU capacity is expensive, scarce, and easy to underutilize. Enterprises that self-host models or operate private inference clusters need workload orchestration strategies that improve utilization without compromising latency or reliability. This includes right-sizing models, scheduling workloads, batching requests, using mixed hardware tiers, and separating real-time workloads from batch workloads.
Autoscaling for AI Workloads
Autoscaling AI inference is more complex than scaling web services. Scaling decisions should consider GPU memory, model load time, request queue depth, concurrency, prompt size, output size, and cold-start impact. For high-volume workloads, pre-warmed capacity may be necessary to avoid unacceptable latency spikes.
Batching and Queue Management
Batching can increase throughput and improve accelerator utilization, but it must be tuned carefully. Aggressive batching can increase latency for interactive workloads. Queue management should prioritize high-value or user-facing requests while moving background tasks into lower-cost execution lanes.
GPU Optimization Guardrail
The goal is not maximum GPU usage at all times. The goal is the right balance of utilization, latency, reliability, cost, and workload priority.
Model Routing and Cost-Efficient Inference
Cost-efficient AI inference requires intentional model routing. Not every request needs the most capable model. Enterprises can reduce cost by using smaller models for simple tasks, specialized models for narrow domains, larger models for complex reasoning, and fallback models when availability or latency becomes an issue. The inference layer should make routing decisions based on business logic, risk, quality requirements, and cost targets.
Complexity-Based Routing
Route simple classification, extraction, and formatting tasks to efficient models while preserving stronger models for complex reasoning.
Risk-Based Routing
Use stricter models, private endpoints, or additional validation for regulated, customer-facing, or high-impact workflows.
Latency-Based Routing
Route interactive workloads toward low-latency endpoints and background workloads toward cost-optimized execution paths.
Availability-Based Routing
Use fallback providers, backup models, regional endpoints, and graceful degradation when primary inference paths fail.
Key Takeaways
- ✓ AI inference infrastructure is the production layer that turns model capability into reliable, low-latency, cost-efficient enterprise AI services.
- ✓ Production AI inference requires model serving, request routing, autoscaling, caching, batching, GPU optimization, observability, and cost governance.
- ✓ Low-latency AI depends on architecture decisions across model choice, prompt size, retrieval performance, streaming, network placement, and endpoint capacity.
- ✓ Cost-efficient inference depends on intelligent model routing, token control, caching, workload prioritization, and capacity planning.
- ✓ Enterprises should treat inference infrastructure as a reusable platform capability, not a one-off model deployment for each AI project.
Caching, Token Control, and Prompt Efficiency
Inference cost is often driven by token usage, repeated context, inefficient prompts, unnecessary model calls, and avoidable retrieval volume. Enterprises need prompt and context optimization as part of infrastructure design. A strong inference layer reduces waste before a model is called and improves reuse wherever safe.
Semantic and Response Caching
Caching can reduce latency and cost for repeated or similar requests. However, caching must respect user permissions, data freshness, personalization, and compliance boundaries. A cached response should never expose information across authorization boundaries.
Prompt Compression and Context Selection
Large prompts and excessive retrieved context increase cost and latency. Inference infrastructure should support context ranking, summarization, prompt templates, compression, and token budgets so the model receives only the information needed for the task.
Efficiency Principle
The cheapest inference request is often the one that is routed correctly, compressed intelligently, cached safely, or avoided entirely through better workflow design.
AI Observability for Inference Reliability
Inference infrastructure must be observable from the beginning. Traditional infrastructure metrics are not enough. Enterprises need to understand how latency, cost, model selection, token volume, cache behavior, request priority, provider health, output quality, and error patterns interact across production workloads.
Operational Metrics
Teams should track time to first token, total response time, queue time, model load time, throughput, GPU utilization, cache hit rate, fallback rate, provider errors, request retries, and endpoint saturation.
Economic Metrics
Inference cost should be visible by application, team, customer segment, workflow, model, provider, token type, and environment. Without cost attribution, enterprises cannot optimize AI economics or hold teams accountable for usage patterns.
Observability Guardrail
If teams cannot see which model served a request, how long it took, how much it cost, why it was routed there, and whether it met quality expectations, the inference platform is not production mature.
Security and Governance in AI Inference Infrastructure
Inference infrastructure is a security boundary. It handles prompts, retrieved context, user identity, model responses, provider requests, usage logs, and sometimes sensitive enterprise data. Security must be built into request routing, model access, endpoint protection, logging, caching, and provider selection.
Access Control
Control which applications, agents, users, and workflows can access specific models, endpoints, and inference policies.
Data Protection
Protect prompts, logs, traces, cached responses, retrieved context, model outputs, and provider-bound data.
Policy Enforcement
Apply routing rules, risk tiers, provider restrictions, safety filters, rate limits, and audit requirements before inference runs.
Common Mistakes
Many enterprises treat inference as a simple API call. That works during experimentation, but it fails when teams need predictable latency, cost governance, secure routing, high availability, and consistent user experience across multiple AI applications.
- Using one model for every workload. This increases cost and latency when smaller or specialized models could serve many tasks effectively.
- Ignoring token economics. Long prompts, excessive context, and inefficient retries can make AI costs unpredictable.
- Scaling only by request count. AI workload scaling must consider prompt size, output length, GPU memory, queue depth, and model load time.
- Skipping inference observability. Without inference telemetry, teams cannot diagnose latency, cost spikes, provider failures, routing mistakes, or capacity issues.
- Caching without authorization boundaries. Unsafe caching can expose sensitive responses across users or workflows.
- Treating model serving as a one-off deployment. Enterprises need reusable inference platform patterns across teams and AI use cases.
Enterprise Architecture Perspective
From an enterprise architecture perspective, AI inference infrastructure is the runtime delivery layer for production AI. It connects applications, model providers, self-hosted models, cloud infrastructure, GPU pools, data systems, RAG pipelines, agent orchestration, identity systems, observability, security, and cost governance. This layer determines whether AI can become an enterprise platform capability instead of a collection of isolated experiments.
The strongest inference architectures standardize common capabilities while allowing flexibility by use case. Teams should not reinvent model serving, routing, monitoring, caching, or cost tracking for every project. At the same time, the architecture must support different latency tiers, privacy requirements, model types, deployment models, and business priorities.
Architecture Principle
AI inference infrastructure should be treated as a governed enterprise platform layer: reusable, observable, secure, cost-aware, and optimized for workload-specific performance.
Implementation Strategy for AI Inference Infrastructure
Enterprises should implement inference infrastructure in phases. The goal is not to build a massive platform before shipping AI. The goal is to create reusable inference capabilities that improve as production demand grows. Start with control, visibility, and workload classification, then mature toward optimization, automation, and multi-model routing.
Phase 1: Classify AI Workloads
Group AI workloads by latency requirement, business criticality, data sensitivity, expected volume, model complexity, quality requirement, and cost tolerance. This prevents overengineering simple workloads and underengineering critical ones.
Phase 2: Build the Inference Gateway
Create a central control point for model access, routing, policies, usage tracking, rate limiting, authentication, provider abstraction, and telemetry. This gives enterprises visibility and governance before usage spreads across teams.
Phase 3: Optimize Performance and Cost
Add model routing, caching, batching, prompt optimization, queue prioritization, autoscaling, and cost attribution. Focus on measurable improvements in latency, throughput, GPU utilization, and cost per workflow.
Phase 4: Operationalize Reliability and Governance
Connect inference telemetry to incident response, capacity planning, executive reporting, governance evidence, security monitoring, and continuous improvement. Mature inference infrastructure should operate like any business-critical production platform.
Implementation Checklist
Foundation
- Inventory production AI workloads
- Classify latency and cost requirements
- Define model serving ownership
- Establish inference gateway patterns
Optimization
- Implement model routing policies
- Use caching with permission controls
- Tune batching and queue management
- Monitor GPU utilization and endpoint saturation
Operations
- Track latency, cost, and model quality
- Create fallback and failover routes
- Connect inference alerts to incident response
- Review cost per workflow regularly
Measuring AI Inference Infrastructure Maturity
AI inference maturity should be measured by how well the enterprise can deliver model responses with consistent latency, reliable uptime, controlled cost, appropriate model selection, and strong operational visibility. A mature organization does not only know that inference endpoints are running. It knows whether they are serving the right workloads efficiently and safely.
Metrics to Track
How YggyTech Helps
YggyTech helps enterprises design and implement AI inference infrastructure for scalable, low-latency, cost-efficient production AI. We help organizations move from direct model API usage and isolated serving endpoints to governed inference platforms that support multiple models, teams, workloads, and business requirements.
Inference Architecture Strategy
We define model serving blueprints, routing strategy, latency tiers, workload classification, cost governance, and production readiness roadmaps.
AI Platform and LLMOps Engineering
We design inference gateways, model endpoints, observability pipelines, caching layers, deployment controls, and secure LLMOps workflows.
Optimization and Operations
We help teams optimize latency, GPU utilization, token usage, model routing, cost attribution, reliability, and incident response.
Our expertise spans enterprise AI, AI infrastructure, LLMOps, cloud architecture, DevOps, observability, security, governance, and scalable software systems. That systems-level perspective matters because inference infrastructure is not only a model-serving problem. It is the enterprise runtime layer for production AI.
Build AI Inference Infrastructure That Scales with Control
YggyTech helps technology leaders build AI inference infrastructure that improves latency, controls cost, optimizes model serving, scales workloads, and brings production AI operations under enterprise-grade governance.
Talk to YggyTechFAQs About AI Inference Infrastructure
What is AI inference infrastructure?
AI inference infrastructure is the production architecture used to serve AI models efficiently. It includes model serving, inference gateways, request routing, GPU and CPU orchestration, caching, batching, autoscaling, observability, security, and cost governance.
Why is AI inference infrastructure important for enterprises?
AI inference infrastructure is important because production AI systems need predictable latency, reliable throughput, controlled cost, secure routing, model availability, and operational visibility. Without it, AI applications become expensive, slow, unreliable, or difficult to govern.
How can enterprises reduce AI inference costs?
Enterprises can reduce AI inference costs by using model routing, smaller models for simple tasks, prompt compression, safe caching, batching, token budgets, GPU utilization monitoring, workload prioritization, and cost attribution by application or workflow.
What is low-latency AI inference?
Low-latency AI inference means serving model responses quickly enough for the use case. It depends on model selection, endpoint capacity, network placement, streaming, caching, prompt size, retrieval performance, batching strategy, and autoscaling.
How should enterprises start building AI inference infrastructure?
Enterprises should start by classifying AI workloads, defining latency and cost targets, creating an inference gateway, standardizing model serving, implementing observability, adding routing policies, and optimizing performance and cost through production telemetry.

Ethan Brooks
Senior AI Systems Strategist
Ethan specializes in enterprise AI architecture, scalable automation systems, and intelligent workflow optimization. At YGGY Tech, he writes about practical AI implementation, cloud-native systems, and how modern businesses can eliminate operational fragmentation through intelligent infrastructure.