AI Operations Runbooks: How Enterprises Standardize Reliability, Escalation, and Continuous Improvement for Production AI
AI operations runbooks give enterprises a repeatable operating model for managing production AI reliability, quality, cost, incidents, escalation, governance, and continuous improvement. As LLM applications, RAG systems, AI agents, and AI-enabled workflows move into production, teams need operational discipline that goes beyond dashboards and model metrics.
Why AI Operations Runbooks Matter
Production AI systems behave differently from traditional software. A conventional application usually fails through observable technical symptoms: downtime, errors, latency spikes, failed jobs, dependency failures, or infrastructure saturation. AI systems can fail in more subtle ways. They can produce low-quality responses, retrieve stale context, use the wrong model, hallucinate, expose sensitive information, exceed cost budgets, misroute agent actions, or degrade user trust while the underlying application still appears technically healthy.
AI operations runbooks help enterprises handle this complexity. They define what teams should do when AI quality drops, model costs spike, retrieval accuracy declines, an agent workflow behaves unexpectedly, a governance policy is violated, or a customer-facing AI feature produces a risky outcome. Instead of relying on ad hoc expert judgment, runbooks turn operational response into a repeatable system.
Key Insight
AI operations is not only about monitoring AI systems. It is about knowing what action to take when production AI behavior changes, who owns the decision, how risk is contained, and how the system improves afterward.
What AI Operations Runbooks Actually Are
AI operations runbooks are structured procedures that guide teams through detection, diagnosis, escalation, containment, recovery, governance review, and continuous improvement for production AI systems. They sit at the intersection of AI observability, LLMOps, DevOps, incident response, governance, security, data operations, and business ownership.
A strong runbook does not only list technical troubleshooting steps. It defines the operational context: which signal triggered the issue, what business process is affected, what risk tier applies, which teams should be notified, what evidence must be preserved, which controls can be adjusted, which fallback path should activate, and how the incident should improve future AI behavior.
Reliability Runbooks
Guide teams through latency, availability, endpoint failure, model fallback, queue saturation, and workflow recovery scenarios.
Quality Runbooks
Handle hallucination risk, retrieval quality decline, prompt regression, unsafe responses, and model behavior drift.
Cost Runbooks
Respond to token spikes, inefficient prompts, model overuse, caching failures, provider cost anomalies, and runaway agent loops.
Governance Runbooks
Define escalation, approval, audit evidence, risk review, policy exceptions, and post-incident accountability.
Why Traditional Operations Runbooks Are Not Enough
Traditional operations runbooks usually assume that a system either works or fails through measurable infrastructure symptoms. They are designed around server health, service availability, request errors, database performance, network conditions, deployment rollback, and dependency failures. These patterns still matter, but AI systems add behavioral, semantic, and governance dimensions that traditional runbooks do not fully capture.
An AI system may be available, fast, and technically successful while still producing incorrect answers. A RAG pipeline may retrieve documents successfully while selecting weak sources. An AI agent may complete a workflow while skipping an approval step. A model may return valid JSON while making a risky recommendation. AI operations runbooks must account for technical health and decision quality together.
Enterprise Signal
A production AI issue may not look like an outage. It may look like reduced confidence, poor retrieval, unsafe output, excessive spend, policy drift, or a workflow outcome that no team can explain.
From Uptime Response to Behavior Response
AI operations teams must respond to behavior changes, not only service failures. This includes changes in answer quality, retrieval accuracy, refusal rate, cost per workflow, prompt success rate, agent completion path, and escalation frequency.
From Technical Ownership to Shared Accountability
Production AI issues often require engineering, data, security, governance, product, legal, and business teams to coordinate. Runbooks define who acts, who approves, and who owns the outcome.
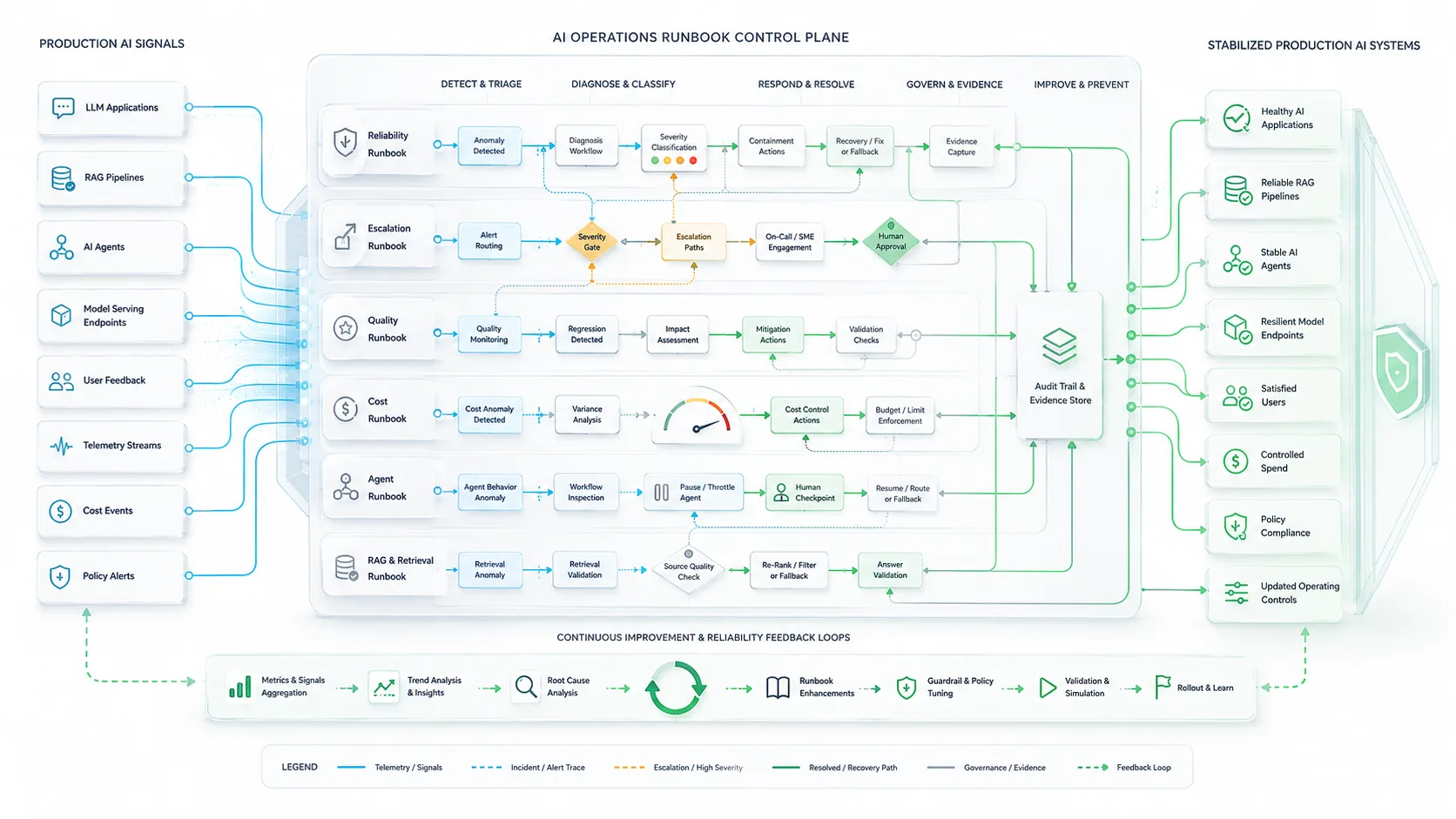
Core Layers of an AI Operations Runbook System
AI operations runbooks should be designed as a system, not as isolated documents. The strongest enterprises connect runbooks to observability signals, incident workflows, ownership models, governance requirements, model lifecycle controls, and post-incident improvement loops.
Reference AI Operations Runbook Layers
Runbooks Should Be Connected to Live Signals
A runbook becomes operationally useful when it is connected to the signals that trigger it. Alerts should map to specific runbooks, severity levels, owners, evidence requirements, and response paths.
Runbooks Should Preserve Evidence
AI incidents require traceability. Teams should preserve prompts, responses, retrieved sources, model versions, tool calls, policy decisions, user context, and escalation history before making changes.
Runbooks for AI Reliability and Availability
Reliability runbooks define how teams respond when production AI systems become slow, unavailable, degraded, or unstable. These runbooks should account for model providers, inference endpoints, retrieval systems, vector databases, orchestration services, agent engines, API gateways, cloud resources, and downstream business applications.
Latency Degradation
Diagnose queue depth, model endpoint saturation, retrieval latency, prompt size, provider slowdown, and regional routing issues.
Endpoint Failure
Activate fallback models, route to alternate providers, degrade gracefully, notify owners, and preserve incident context.
Workflow Interruption
Pause risky workflow steps, preserve state, reroute to human review, recover from checkpoint, and notify affected teams.
Reliability Principle
A production AI system should have known fallback paths before failure happens: alternate models, simplified prompts, cached responses, human escalation, or safe workflow degradation.
Runbooks for AI Quality and Model Behavior
AI quality issues require a different response path from infrastructure outages. A model may be available and fast while producing unreliable answers. Quality runbooks help teams diagnose whether the issue comes from prompts, retrieval quality, model version changes, evaluation gaps, user input patterns, safety rules, or downstream workflow assumptions.
Hallucination and Unsupported Claims
When unsupported claims increase, teams should review retrieved evidence, prompt instructions, model temperature, source ranking, output constraints, and evaluation results. The runbook should define when to reduce autonomy, require citations, add refusal behavior, or route to human review.
Retrieval Quality Decline
RAG systems can degrade when documents become stale, indexing fails, chunking strategy is weak, metadata is incomplete, or permission filters remove relevant context. Retrieval runbooks should guide teams through source freshness, vector index health, search relevance, and knowledge pipeline validation.
Quality Guardrail
AI quality incidents should feed directly into evaluation datasets, retrieval improvements, prompt changes, and governance review. Quality failures should not be treated as one-off user complaints.
Runbooks for AI Cost and Capacity Operations
AI cost operations require dedicated runbooks because spending can increase quickly through token growth, inefficient prompts, repeated retries, unnecessary large-model usage, poor caching, agent loops, and ungoverned experimentation. Cost runbooks should define when to investigate, when to throttle, when to reroute, and when to redesign workflows.
Token Spike
Review prompt length, context size, output length, retries, user segments, workflow changes, and new feature launches.
Model Overuse
Route simple tasks to smaller models, apply complexity-based routing, and reserve premium models for high-value workflows.
Caching Failure
Investigate cache hit rate, permission boundaries, context freshness, invalidation rules, and repeated query patterns.
Agent Loop
Limit retry counts, cap tool calls, enforce workflow timeouts, and escalate repeated failures to human review.
Key Takeaways
- ✓ AI operations runbooks standardize how enterprises detect, diagnose, escalate, contain, recover, and improve production AI systems.
- ✓ Production AI operations must manage reliability, quality, cost, governance, security, agent behavior, retrieval performance, and business impact together.
- ✓ Traditional operations runbooks are not enough because AI failures can be semantic, behavioral, financial, or governance-related rather than purely technical.
- ✓ Strong runbooks connect live observability signals to evidence collection, ownership, escalation, fallback paths, and post-incident learning.
- ✓ Mature AI operations converts every production issue into better evaluations, prompts, retrieval controls, model routing, policies, and runbooks.
Runbooks for Agentic AI Workflows
AI agents require specialized operations runbooks because they can take action, not only produce responses. An agent may call APIs, update records, execute workflows, trigger notifications, retrieve data, open tickets, or coordinate with other agents. When agent behavior changes, operations teams need clear guidance for containment, review, rollback, and approval.
Unsafe Tool Use
If an agent calls an unexpected tool or uses an approved tool in a risky way, the runbook should pause the workflow, preserve the tool-call trace, review permission boundaries, notify the owner, and determine whether action reversal or customer communication is required.
Workflow State Drift
Agent workflows can drift when intermediate steps fail, memory is stale, context is incomplete, or tool output is misinterpreted. Runbooks should define checkpoints, state validation, retry limits, escalation conditions, and safe recovery paths.
Agent Operations Principle
Every autonomous workflow should have a safe-stop mechanism, human escalation path, audit trail, and rollback or compensation strategy before production deployment.
Escalation Models for Production AI
AI operations runbooks must define escalation clearly. Many AI issues are cross-functional by nature. A technical team may diagnose the model or retrieval pipeline, but the business owner may decide whether the output is acceptable. Security may handle data exposure. Governance may review policy impact. Product may manage user communication. Legal or compliance may be required for regulated workflows.
Technical Escalation
Routes issues to platform, data, model, application, DevOps, or LLMOps owners for diagnosis and recovery.
Business Escalation
Involves product, operations, customer support, or process owners when AI behavior affects business outcomes.
Risk Escalation
Engages security, privacy, compliance, legal, or governance teams for high-impact or regulated AI incidents.
Escalation Guardrail
A production AI runbook should make escalation unambiguous: who is paged, who decides, who approves containment, who communicates impact, and who owns the post-incident improvement plan.
Governance and Audit Evidence in AI Operations
AI operations runbooks should collect governance evidence automatically wherever possible. Production incidents, quality exceptions, model changes, prompt updates, policy overrides, agent approvals, fallback activations, and human review decisions should be traceable. This evidence supports internal accountability, compliance readiness, risk management, and executive reporting.
What Evidence Should Be Captured
Teams should preserve the triggering alert, affected system, user segment, prompt and response samples, retrieved sources, model version, prompt version, agent tool calls, policy checks, approval records, remediation steps, and final resolution summary.
Why Evidence Improves Operations
Evidence is not only for compliance. It helps engineering teams understand what happened, helps governance teams assess risk, helps product teams communicate clearly, and helps leaders prioritize system improvements based on real production behavior.
Governance Operations Principle
A runbook should not end with recovery. It should end with evidence, accountability, root-cause learning, and a concrete update to the AI operating model.
Common Mistakes
Many enterprises deploy AI observability tools without operational runbooks. The result is more data but not necessarily better response. AI operations maturity depends on turning signals into action, ownership, governance, and improvement.
- Treating AI issues as generic application incidents. AI failures may involve quality, retrieval, model behavior, prompt regressions, governance, or workflow outcomes.
- Creating alerts without response paths. Every important alert should map to an owner, runbook, severity level, and escalation workflow.
- Ignoring business ownership. Engineering can diagnose system behavior, but business owners must help assess operational impact.
- Skipping evidence collection. Without traces, prompts, retrieved sources, model versions, and policy decisions, teams cannot learn from incidents reliably.
- Over-relying on manual expert response. AI operations should be repeatable enough for on-call teams, not dependent on one senior engineer.
- Failing to update the runbook. Every AI incident should improve future response procedures, evaluation coverage, and system controls.
Enterprise Architecture Perspective
From an enterprise architecture perspective, AI operations runbooks are the human and procedural layer of production AI architecture. Infrastructure, observability, governance, and security controls are necessary, but they do not replace operational decision-making. Runbooks define how the enterprise acts when AI systems behave unexpectedly.
The strongest AI operating models treat runbooks as living architecture. They connect to production telemetry, risk tiers, ownership models, model lifecycle controls, knowledge systems, agent permissions, cost governance, and incident response. This makes AI operations more resilient because teams are not inventing procedures during incidents.
Architecture Principle
Production AI systems should be designed with operational runbooks before launch, not after the first incident exposes ownership gaps.
Implementation Strategy for AI Operations Runbooks
Enterprises should implement AI operations runbooks in phases. The objective is not to document every possible issue upfront. The objective is to create a practical operating foundation that improves as production AI systems mature.
Phase 1: Identify Production AI Failure Modes
Map the most likely failure modes across AI applications, RAG systems, agents, model serving, data pipelines, observability, cost management, security, and governance. Prioritize high-impact systems first.
Phase 2: Connect Signals to Runbooks
Define which observability signals trigger each runbook. Include severity, owner, escalation path, required evidence, containment action, and communication requirements.
Phase 3: Standardize Response and Recovery
Document the steps for diagnosis, rollback, fallback activation, workflow pause, human review, cost throttling, prompt freeze, model routing changes, and incident closure.
Phase 4: Build Continuous Improvement Loops
Use every incident to update evaluations, prompts, retrieval systems, model routing, agent controls, governance policies, cost thresholds, and the runbook itself.
Implementation Checklist
Foundation
- Inventory production AI systems
- Map failure modes by system type
- Assign business and technical owners
- Define severity levels and risk tiers
Runbook Design
- Connect alerts to runbooks
- Define evidence collection requirements
- Document containment and fallback paths
- Set escalation and communication rules
Operations
- Review runbooks after incidents
- Update evaluations and controls
- Track response and recovery metrics
- Train on-call and cross-functional teams
Measuring AI Operations Runbook Maturity
AI operations maturity should be measured by how consistently teams can detect, diagnose, escalate, contain, recover, and improve production AI systems. A mature organization does not only know that something went wrong. It knows what happened, why it happened, who owned the response, how impact was contained, and what changed afterward.
Metrics to Track
How YggyTech Helps
YggyTech helps enterprises design AI operations runbooks and operating models for production AI systems. We help organizations move from informal AI monitoring to structured operational response across reliability, quality, cost, governance, security, agents, RAG systems, and LLMOps workflows.
AI Operations Strategy
We define AI operating models, ownership structures, runbook systems, escalation workflows, production readiness criteria, and maturity roadmaps.
Production AI Reliability Engineering
We design observability signals, incident workflows, fallback paths, cost controls, evaluation feedback loops, and operational dashboards.
Governance and LLMOps Integration
We connect AI operations with model lifecycle management, RAG operations, agent controls, governance evidence, security response, and enterprise reporting.
Our expertise spans enterprise AI, AI operations, LLMOps, cloud architecture, DevOps, cybersecurity, AI governance, software architecture, and scalable systems. That systems-level perspective matters because AI operations runbooks must connect technology behavior with business accountability.
Operationalize Production AI Before Incidents Define the Process
YggyTech helps technology leaders build AI operations runbooks that standardize reliability, escalation, governance, cost control, incident response, and continuous improvement across production AI systems.
Talk to YggyTechFAQs About AI Operations Runbooks
What are AI operations runbooks?
AI operations runbooks are structured procedures for detecting, diagnosing, escalating, containing, recovering, and improving production AI systems when reliability, quality, cost, governance, security, or workflow issues occur.
Why do enterprises need AI operations runbooks?
Enterprises need AI operations runbooks because production AI can fail through quality drift, retrieval errors, model behavior changes, cost spikes, unsafe agent actions, policy violations, and business workflow impact, not only technical outages.
What should an AI operations runbook include?
An AI operations runbook should include trigger signals, severity levels, system owners, evidence collection steps, diagnosis workflow, containment actions, escalation paths, fallback options, communication requirements, and post-incident improvement actions.
How are AI operations runbooks different from DevOps runbooks?
DevOps runbooks focus mainly on application, infrastructure, deployment, and availability issues. AI operations runbooks add model behavior, prompt quality, retrieval accuracy, agent actions, evaluation results, token costs, policy decisions, and governance evidence.
How can organizations start building AI operations runbooks?
Organizations should start by inventorying production AI systems, mapping likely failure modes, connecting observability alerts to owners, defining severity levels, creating response procedures, preserving incident evidence, and updating runbooks after every meaningful production event.

Ava Mitchell
UX & Digital Experience Strategist
Ava combines product psychology, interface systems, and user-centered design to create digital experiences that feel intuitive and scalable. Her work at YGGY Tech focuses on high-conversion UX systems, enterprise interfaces, and design-driven growth.