How Enterprises Are Building AI Reliability Engineering Teams
Over the last decade, Site Reliability Engineering (SRE) transformed how organizations managed software systems at scale. Today, a similar transformation is occurring in enterprise AI.
As artificial intelligence moves into mission-critical operations, organizations are discovering that traditional engineering, infrastructure, and data teams alone cannot adequately manage the complexity of modern AI systems.
Models drift. Agents behave unpredictably. Context changes. Inference latency spikes. Knowledge systems evolve. Governance requirements expand.
As a result, a new organizational function is emerging across forward-thinking enterprises: AI Reliability Engineering (AIRE).
AI Reliability Engineering teams are becoming responsible for ensuring AI systems remain reliable, observable, secure, governed, resilient, and operationally effective at scale.
The Rise of AI Reliability Engineering
Traditional software systems generally produce deterministic outputs. Given the same input, the application behaves predictably.
AI systems introduce entirely new operational challenges:
- Non-deterministic behavior
- Model degradation over time
- Prompt variability
- Context inconsistency
- Knowledge drift
- Agent coordination failures
- Inference bottlenecks
- Governance risks
These challenges require specialized operational expertise that sits between AI development and production operations.
AI Reliability Engineering fills this gap.
What Is AI Reliability Engineering?
AI Reliability Engineering applies reliability principles to AI infrastructure, models, agents, orchestration systems, and operational workflows.
The objective is not simply to keep systems online.
The objective is to ensure AI systems consistently deliver trustworthy, performant, and governed outcomes under real-world conditions.
Core Responsibilities Include:
- AI observability
- Inference reliability
- Model performance monitoring
- Agent orchestration reliability
- Operational resilience
- Governance enforcement
- Incident response
- Reliability automation
Why Enterprises Need Dedicated AI Reliability Teams
As organizations deploy hundreds of models, autonomous workflows, and multi-agent systems, reliability challenges multiply rapidly.
AI systems now influence:
- Customer operations
- Financial decision-making
- Supply chain execution
- Healthcare workflows
- Cybersecurity operations
- Software engineering platforms
- Operational intelligence systems
Failures in these environments can create significant business impact.
Organizations increasingly recognize that AI reliability requires dedicated ownership.
The Structure of Modern AI Reliability Engineering Teams
AI Reliability Engineers
These engineers focus on operational health, observability, incident management, and infrastructure stability for AI systems.
Responsibilities include:
- Reliability metrics
- Monitoring frameworks
- Operational diagnostics
- Failure analysis
- Performance optimization
AI Platform Engineers
Platform engineers provide the infrastructure foundation supporting AI operations.
They manage:
- Inference platforms
- GPU orchestration
- Model deployment systems
- Control planes
- Platform automation
AI Observability Specialists
Observability has become a dedicated discipline within AI operations.
These specialists monitor:
- Inference latency
- Model quality
- Context utilization
- Agent interactions
- Workflow execution paths
- Governance compliance
AI Governance Engineers
As regulatory requirements expand, governance specialists are increasingly embedded within reliability teams.
They ensure:
- Policy compliance
- Auditability
- Security enforcement
- Access controls
- Operational accountability
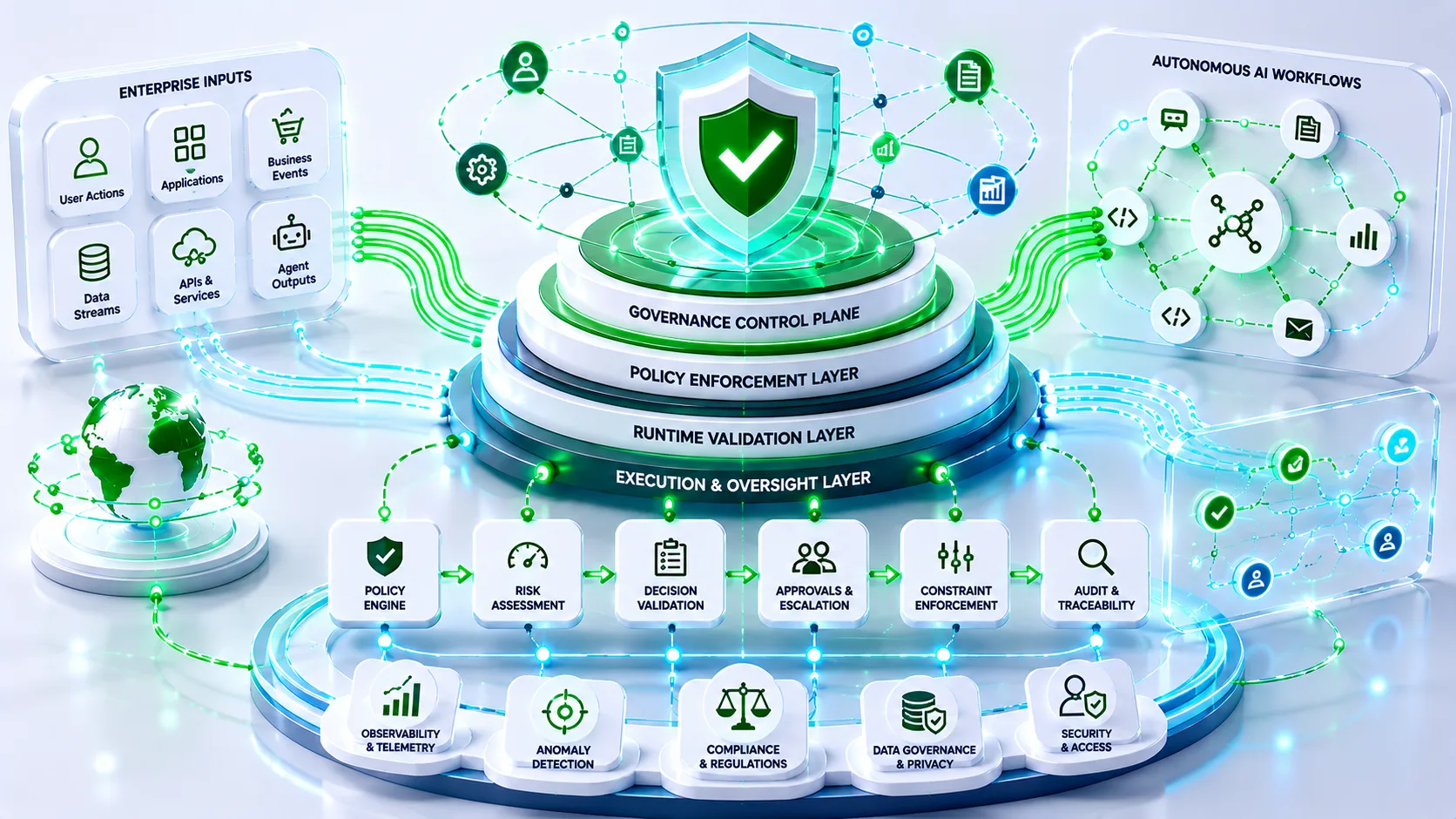
The Five Pillars of AI Reliability Engineering
1. Observability
You cannot improve what you cannot see.
AI observability platforms provide visibility into:
- Model behavior
- Agent execution
- Context usage
- Workflow health
- Infrastructure performance
Observability forms the foundation of reliability.
2. Performance
Mission-critical AI systems must consistently meet latency and throughput objectives.
Reliability teams establish operational targets and continuously monitor adherence.
Typical metrics include:
- Inference response times
- Execution success rates
- Workflow completion rates
- Agent coordination efficiency
3. Resilience
Modern AI systems must continue operating despite failures.
Reliability teams design:
- Failover mechanisms
- Recovery workflows
- Redundancy architectures
- Incident response systems
- Self-healing infrastructure
4. Governance
Reliability extends beyond uptime.
Enterprises increasingly define reliable AI as AI that remains compliant, secure, and auditable.
Governance becomes part of operational reliability.
5. Automation
Manual operations cannot scale alongside enterprise AI growth.
Reliability teams automate:
- Monitoring
- Alerting
- Incident response
- Policy enforcement
- Infrastructure recovery
AI Reliability Metrics Enterprises Are Tracking
Leading organizations are developing new reliability indicators specifically designed for AI systems.
Operational Metrics
- Inference latency
- Availability
- Error rates
- Throughput
- Resource utilization
AI-Specific Metrics
- Model accuracy drift
- Context quality scores
- Hallucination rates
- Agent coordination success rates
- Knowledge freshness indicators
Governance Metrics
- Policy compliance rates
- Audit coverage
- Security incidents
- Access-control violations
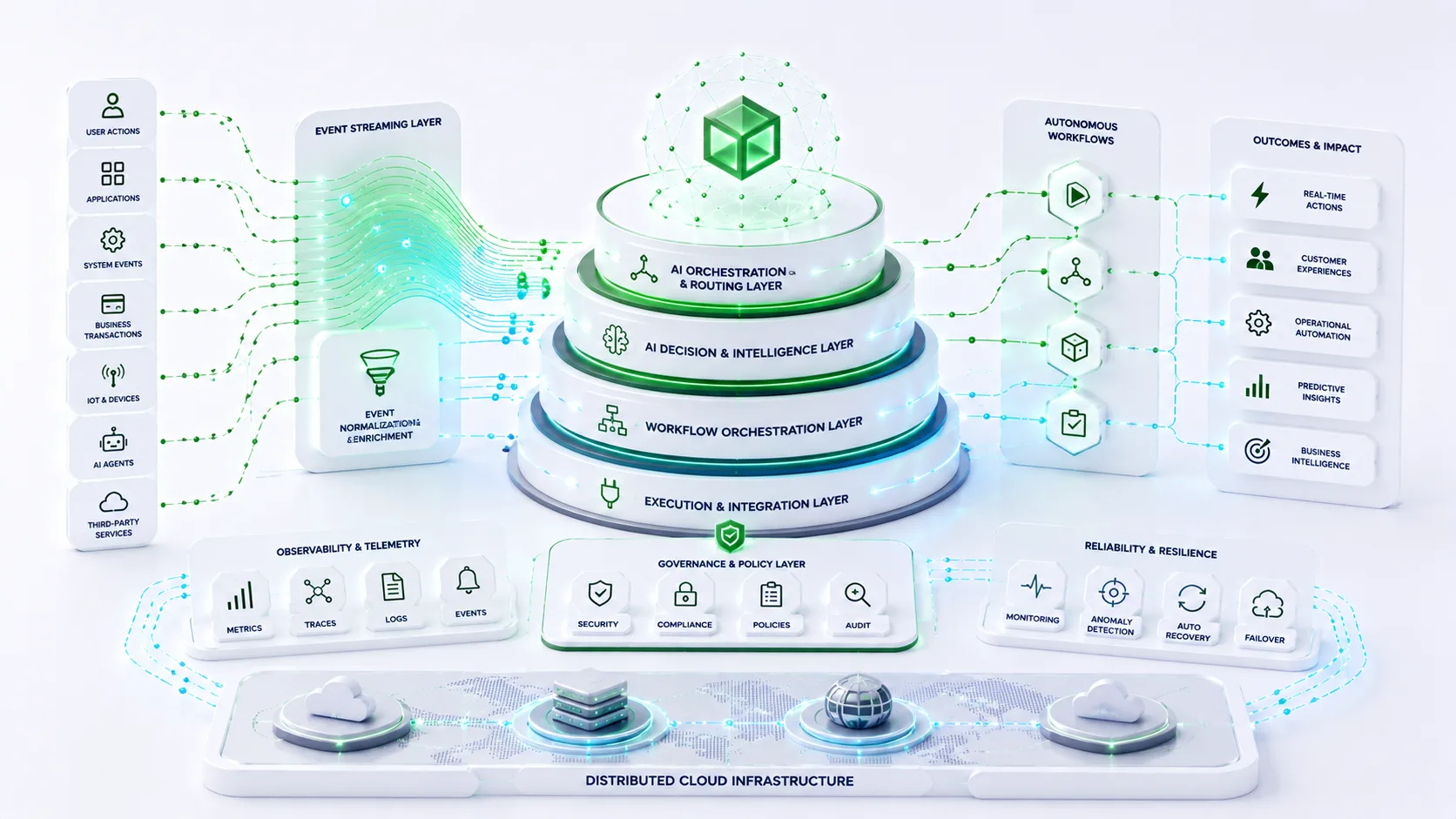
The Impact of Multi-Agent Systems
One of the biggest drivers behind AI Reliability Engineering is the rise of multi-agent architectures.
Modern enterprises increasingly deploy specialized agents responsible for:
- Research
- Planning
- Operations
- Security
- Customer support
- Workflow orchestration
Reliability teams ensure these agents collaborate effectively without introducing operational instability.
AI Reliability Engineering and Platform Engineering
Many organizations are integrating AI Reliability Engineering with Platform Engineering initiatives.
AI-native Internal Developer Platforms increasingly provide:
- Standardized AI deployment workflows
- Built-in observability
- Governance automation
- Reliability guardrails
- Operational monitoring systems
This enables engineering teams to innovate while maintaining operational consistency.
Common Challenges Enterprises Face
- Limited AI observability maturity
- Rapidly changing model ecosystems
- Fragmented infrastructure ownership
- Insufficient governance integration
- Agent orchestration complexity
- Lack of AI-specific operational expertise
Organizations that address these challenges early gain significant operational advantages.
Building an AI Reliability Engineering Team
Enterprises beginning their AI reliability journey should focus on:
- Establishing AI observability foundations
- Defining reliability metrics
- Creating governance integration processes
- Implementing incident response workflows
- Building operational intelligence platforms
- Automating reliability operations
- Creating dedicated AI reliability ownership
The most successful organizations treat AI reliability as a strategic capability rather than an infrastructure function.
The Future of AI Reliability Engineering
By 2027, AI Reliability Engineering is expected to become a standard organizational function across enterprises operating large-scale AI systems.
Much like SRE became essential for cloud-native software operations, AI Reliability Engineering will become essential for autonomous enterprise operations.
The organizations that invest early will be best positioned to scale AI safely, reliably, and efficiently.
Key Takeaways
- AI Reliability Engineering is emerging as a dedicated enterprise discipline.
- Reliability now includes observability, governance, resilience, and operational intelligence.
- Multi-agent systems are increasing the need for specialized operational teams.
- AI observability serves as the foundation of reliability programs.
- Platform Engineering and AI Reliability Engineering are increasingly converging.
How YggyTech Helps
YggyTech helps enterprises build modern AI Reliability Engineering capabilities through observability platforms, operational intelligence systems, AI control planes, governance frameworks, reliability automation, and cloud-native AI infrastructure.
Our expertise enables organizations to deploy mission-critical AI systems with confidence, resilience, and operational maturity.
Conclusion
As AI becomes embedded within core business operations, reliability can no longer be treated as an afterthought.
Enterprises are recognizing that successful AI adoption depends not only on building intelligent systems but also on operating them reliably at scale.
AI Reliability Engineering teams are becoming the operational backbone that makes this possible.
FAQs
What is AI Reliability Engineering?
AI Reliability Engineering focuses on ensuring AI systems remain reliable, observable, governed, secure, and operationally effective in production environments.
How is AI Reliability Engineering different from SRE?
SRE focuses primarily on software reliability, while AI Reliability Engineering addresses AI-specific challenges such as model drift, agent coordination, context quality, and governance.
Why are enterprises creating AI Reliability Engineering teams?
AI systems are increasingly mission-critical, requiring dedicated operational ownership to maintain performance, reliability, and compliance.
What skills are needed for AI Reliability Engineering?
Key skills include observability, infrastructure engineering, AI operations, platform engineering, governance, incident response, and cloud-native architecture.
What technologies support AI Reliability Engineering?
Observability platforms, AI control planes, telemetry systems, governance frameworks, orchestration tools, and inference infrastructure platforms are commonly used.

Liam Walker
Product & AI Research Analyst
Liam researches emerging AI tools, automation workflows, and next-generation digital products. He contributes fresh perspectives on startup technology trends, AI productivity systems, and modern SaaS innovation for fast-growing companies.