Inference Infrastructure at Scale: What Enterprises Need in 2026
Enterprise AI infrastructure is entering a new phase. Organizations are no longer experimenting with isolated models or small-scale deployments. They are now operating distributed inference systems supporting real-time decision intelligence, autonomous workflows, AI agents, operational copilots, and mission-critical enterprise automation.
As AI adoption accelerates, inference infrastructure has become one of the most strategically important layers in modern enterprise architecture.
Strategic Infrastructure Shift
The enterprise AI race is no longer just about training better models. In 2026, operational advantage increasingly depends on scalable inference infrastructure capable of delivering resilient, governed, low-latency AI execution across distributed environments.
What Is Inference Infrastructure?
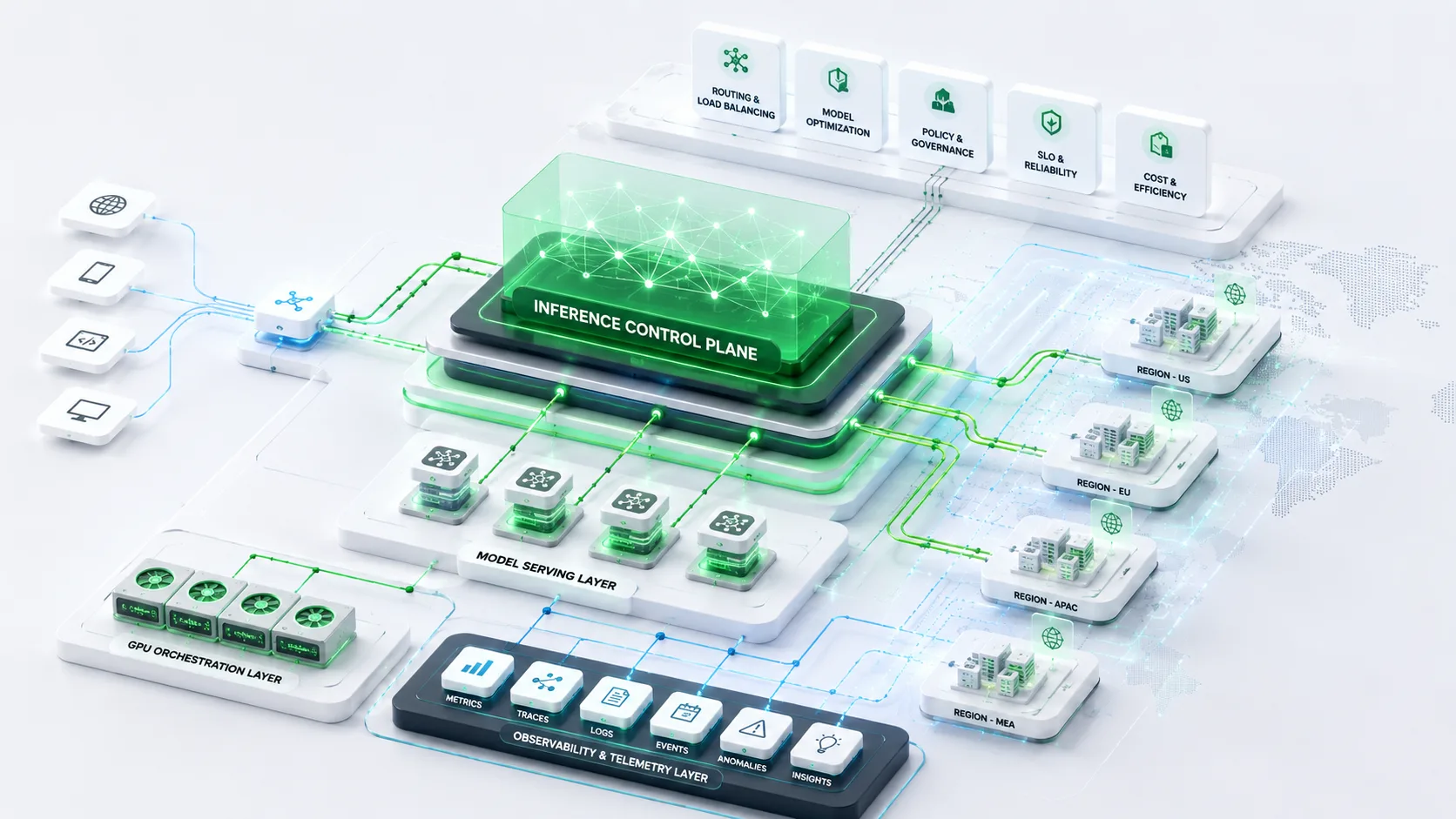
Inference infrastructure refers to the operational systems responsible for serving AI models in production environments. It includes the orchestration, runtime execution, scaling, observability, governance, and optimization layers required to execute AI workloads reliably at enterprise scale.
Unlike model training infrastructure, which focuses on building models, inference infrastructure focuses on operational execution.
Model Serving
Delivering AI model responses reliably and efficiently across enterprise systems.
GPU Orchestration
Managing compute allocation, scaling, and resource scheduling for AI workloads.
Runtime Observability
Tracking latency, failures, telemetry streams, throughput, and operational behavior.
Inference Governance
Applying runtime policies, execution boundaries, and compliance controls.
Why Inference Infrastructure Is Becoming Critical
Modern enterprise AI systems generate significantly more runtime complexity than earlier AI deployments.
Organizations are now operating:
- Autonomous AI agents
- Real-time inference pipelines
- Distributed workflow orchestration systems
- Enterprise copilots
- Operational AI automation layers
- Low-latency decision intelligence systems
- Multi-region inference workloads
The Scaling Reality
Most enterprise AI systems fail operationally before they fail technically. Inference bottlenecks, GPU saturation, orchestration instability, observability gaps, and governance limitations become the primary constraints at scale.
Core Components of Modern Inference Infrastructure
Distributed Model Serving
Modern inference environments require distributed serving architecture capable of routing AI workloads dynamically across regions, environments, and infrastructure tiers.
Inference systems must support:
- Dynamic workload balancing
- Multi-model orchestration
- Low-latency routing
- High-availability execution
- Cross-region failover
GPU Resource Orchestration
GPU infrastructure has become one of the most operationally sensitive layers in enterprise AI environments.
Organizations must optimize:
Workload Scheduling
Dynamic compute allocation for real-time inference demand.
Inference Prioritization
Ensuring mission-critical AI systems receive operational priority.
Resource Efficiency
Reducing infrastructure waste while maintaining runtime reliability.
Inference Observability
Operational visibility is becoming foundational for enterprise AI systems.
Inference observability includes:
- Latency monitoring
- Execution tracing
- Anomaly detection
- Infrastructure telemetry
- Inference reliability metrics
- Operational throughput analysis
Observability Is No Longer Optional
As inference systems become increasingly autonomous, enterprises need continuous visibility into runtime behavior, execution pathways, and operational anomalies across AI infrastructure.
Architectural Trends Shaping 2026
Inference Control Planes
Centralized control planes are emerging to coordinate distributed inference environments, governance systems, and runtime orchestration.
Edge Inference Expansion
Enterprises are increasingly moving inference closer to operational environments to reduce latency and improve resilience.
Hybrid Infrastructure Models
Organizations are combining cloud, on-premise, and edge environments into unified inference ecosystems.
Adaptive Runtime Optimization
Modern infrastructure systems continuously optimize model routing, execution priorities, and resource utilization dynamically.
Operational Challenges Enterprises Face
- GPU resource saturation
- Inference latency instability
- Operational observability gaps
- Cross-region orchestration complexity
- Escalating infrastructure costs
- Runtime governance fragmentation
- Infrastructure resilience limitations
- Scaling autonomous AI workloads
Implementation Strategy for Enterprise Teams
Start with Operational Telemetry
Before optimizing scale, enterprises must first establish complete observability visibility across inference systems.
Build Modular Serving Architecture
Inference systems should remain modular, flexible, and decoupled from specific model implementations.
Introduce Governance Early
Runtime governance becomes significantly harder to implement after inference systems scale operationally.
Phase 1
Telemetry and operational visibility.
Phase 2
Distributed serving and orchestration.
Phase 3
Adaptive scaling and runtime governance.
Common Enterprise Mistakes
- Focusing only on model quality instead of operational scalability
- Underestimating observability requirements
- Treating inference as isolated infrastructure
- Over-centralizing GPU workloads
- Ignoring runtime governance architecture
- Failing to implement resilience orchestration
- Building tightly coupled serving environments
Enterprise Inference Infrastructure Checklist
- Implement distributed model serving architecture
- Deploy runtime observability pipelines
- Establish GPU orchestration systems
- Create inference failover mechanisms
- Introduce runtime governance checkpoints
- Optimize multi-region inference routing
- Build scalable telemetry infrastructure
- Continuously monitor latency and throughput
- Develop resilient workload recovery systems
Key Takeaways
- Inference infrastructure is becoming foundational enterprise architecture.
- Operational scalability now matters as much as model capability.
- Observability and governance are critical runtime requirements.
- GPU orchestration is emerging as a strategic operational discipline.
- Resilient inference systems enable autonomous enterprise AI operations.
How YggyTech Helps
YggyTech helps organizations design enterprise-grade inference infrastructure capable of supporting autonomous AI systems, distributed orchestration environments, and operational-scale AI execution.
Inference Architecture
Designing scalable AI serving systems for enterprise environments.
Operational Observability
Building telemetry, tracing, and runtime visibility systems.
Runtime Governance
Implementing governance and resilience architecture for AI infrastructure.
Build Scalable Enterprise AI Infrastructure
Modern enterprise AI systems require resilient inference infrastructure, runtime visibility, governance maturity, and scalable operational orchestration. YggyTech helps organizations architect AI infrastructure designed for operational intelligence and enterprise-scale execution.
Talk to YggyTechFAQs
What is inference infrastructure?
Inference infrastructure refers to the operational systems responsible for serving AI models in production environments at scale.
Why is inference infrastructure important in 2026?
As enterprises deploy autonomous AI systems and large-scale AI operations, scalable inference infrastructure becomes essential for reliability, latency optimization, governance, and operational resilience.
What role does observability play in inference systems?
Observability provides visibility into AI execution behavior, latency, infrastructure health, operational anomalies, and workload performance.
How do enterprises scale AI inference?
Enterprises scale inference using distributed serving systems, GPU orchestration, runtime optimization, telemetry visibility, and resilient infrastructure architecture.
What are the biggest challenges in enterprise inference infrastructure?
The biggest challenges include GPU scaling, inference latency, runtime governance, observability gaps, infrastructure resilience, and orchestration complexity.

Ava Mitchell
UX & Digital Experience Strategist
Ava combines product psychology, interface systems, and user-centered design to create digital experiences that feel intuitive and scalable. Her work at YGGY Tech focuses on high-conversion UX systems, enterprise interfaces, and design-driven growth.